SQL 조건문
에디터 : SQL Developer
연습할 데이터 기준(예제 직접 타이핑)

SELECT
IN : 한 필드에서 검색하고자 하는 값이 많을 때 묶어서 사용 ( % 이용한 검색은 불가능)

--일부 컬럼(열) 조회
select 속성명1, 속성명2, ... from 테이블명;

-- 조건식 (<>는 해당값이 아닌것을 조회함(null값 제외))
select * from 테이블명 where tel<>'010';

-- null 값 조회
select * from 테이블명 where 속성명 = null;
-- AND 조건(조건 모두다 만족)
select * from member where dept = 'SL' AND username = 'aaa';

-- OR 조건(조건 한가지만 만족해도)
select * from member where name = 'aaa' OR name = 'ppp';

-- NOT 조건(조건에 해당하지 않는 것.)
select * from member where not tel='010';

-- 패턴매칭(like)
-- select * from 테이블명 where 컬럼명 like '문자(열)';
-- % : 임의의 문자 또는 문자열, 빈 문자열
-- _ : 임의의 문자 한개
select * from member where tel like '%010%';

select * from member where tel like '%\%%' ESCAPE '\';

- 아무 문자만 등록해준다음 해당 ' % ' 나 ' _ ' 앞에 명시해주면 like로서의 해당 역할에서 탈출시켜주는것이다.
-- order by로 정렬하기
-- where 조건식 뒤에 [order by 컬럼명]을 추가해서 원하는 순서대로 정렬할 수 있다.
--
-- 기본값이 오름차순이고 내림차순 정렬하러면 [order by 컬럼명 desc]로 지정함
-- (오름차순은 asc임 생략가능)
-- rownum 조건 : 레코드 수 제한
select * from 테이블명 where rownum < 수 order by 속성명 [asc|desc];
select * from member order by name desc;

-- 복수열을 지정해서 정렬하기
-- 정렬하려는 컬럼이 복수일 경우
-- order by 컬렴명1 [asc|desc], 컬럼명2 [asc|desc]...
select * from member order by id desc, name;

-- null 값 정렬
-- oracle은 null 값을 가장 큰 값으로 취급한다.
-- 별명(alias)
-- 테이블의 컬럼명을 원래 이름이 아닌 다른 이름을 사용 가능함 as 키워드 사용(생략 가능)
-- select 컬럼명1 as 별명1, 컬렴명2 as 별명2 from ....
-- 별명으로 특수문자나 한글, 또는 sql 예약어를 사용할 경우 " " (큰 따옴표)로 묶어줌
select name as "별명", id as "이름" from member;
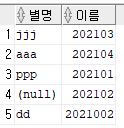
--컬럼간 연산과 별명 사용
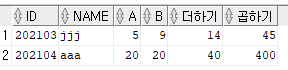
--각 컬럼끼리 연산하는 것이 가능하고 연산 결과는 가상 컬럼으로 처리 가능(테이블에 저장되는 것이 아님)
select id, name, a, b, a+b AS "더하기", a*b AS "곱하기" from member;

--where절이나 order by절에서도 사용 가능함
select id, name, a, b, a+b AS "더하기", a*b AS "곱하기" from member where a+b > 4;
-여기서 sql으 내부적으로 where 구문을 먼저 처리하고 select절을 처리하기 때문에 select절에서 지정한
-별명을 where 절에서 사용하려고 하면 에러를 발생시킴
집계합수(COUNT, SUM)와 중복제거인 DISTINCT
대표적 집계함수 COUNT
- select count(집합) from 테이블명 where 조건식
- 테이블 전체 행 숫자를 알고 싶으면 count(*)를 사용하고, 특정 컬럼의 숫자를 확인하려면 count(컬럼명)을 사용한다.
select COUNT(*) from member;
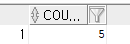
select COUNT(name), count(a), count(b) from member;

총 8행이 있는 테이블이지만 count 로 집계해서 출력한다
중복값은 포함하여 집계
중복값을 제외하고 COUNT 하기 위해서는 DISTINCT 키워드를 사용함
select DISTINCT tel from member;

select count(tel), count(distinct tel) from member;

-- sum avg min max 사용법은 count와 동일
그룹별로 묶어서 집계하기 GROUP BY
구하려는 값이 전체 행의 갯수가 아닌 그룹별로 집계하려고 한다면 group by를 사용
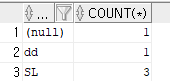
dept 값으로 숫자 구하기
select dept, count(*) from member group by dept;
평균 구하기
select dept, AVG(a) from member group by dept;

- group by 절에서 그룹으로 묶는 컬럼이 아닌 다른 컬럼은 select문에 포함되면 안된다.
having 절
group by 절에 의해서 생긴 각 그룹에 대해서 조건을 적용하려면 having절을 사용해야한다.
select dept, count(*) from member group by dept;

group by로 dept로 묶은 다음 인원이 3명이상인 dept만 출력하는 쿼리문
select dept, count(*) from member group by dept having count(*) < 3;
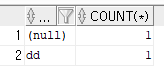
서브쿼리(Sub query)는 sql 문장의 하부 절에 쿼리문을 사용하는 것
메인쿼리의 select문 하부의 where절이나 from 절에서 사용되는 쿼리를 서브쿼리라 한다.
(Inner 쿼리라고도 함)
member 테이블에서 ppp보다 a의 값이 큰 사람을 조회
select name, a from member where a > (select a from member where name='ppp');

주의사항
- 연산자의 오른쪽에 위치해야함
- 괄호로 묶어주어야 함.
제약조건(constraint) : 테이블에 잘못된 데이터의 입력을 막기위해 일정한 규칙을 지정하는 것
SQL 여러가지 제약을 사용가능함.
제약조건 종류
NOT NULL : NULL 값 입력 금지
UNIQUE : 중복값 입력 금지(NULL은 가능)
PRIMARY KEY : NOT NULL + UNIQUE
FOREIGN KEY : 다른 테이블의 컬럼을 조회해서 무결성 검사
CHECK : 조건으로 설정된 값만 입력 허용
제약조건은 CREATE TABLE 명령으로 테이블을 생성할 때 테이블에 대해서 제약을 걸 수도 있고 컬럼에
제약을 걸 수도 있다.
컬럼 레벨의 제약조건은 컬럼을 정의할 때 컬럼별로 지정하는 제약조건으로 특히 NOT NULL 제약조건은
컬럼 레벨에서만 정의할 수 있다.
CREATE TABLE test01(
aa number Primary Key,
bb number not null UNIQUE,
cc varchar(10),
pej varchar(20)
);
CREATE TABLE test02(
ee number not null,
ff number not null,
gg varchar(10),
primary key(ee,ff)
-- 한 개의 제약을 복수의 컬럼에 설정
);
제약조건에 이름 붙이기
CONSTRAINT 키워드
이름을 지정하지 않으면 자동으로 생성되는데 나중에 제약조건을 비활성화하거나 삭제하는 등의 관리를
위해서는 제약조건에 이름을 지정해주는 것이 좋다.
create table test03(
hh number constraint test_hh_pk Primary Key,
ii number constraint test_ii_uk Unique,
jj varchar(10) constraint test_jj_nn not null
);
제약조건 조회하기
ALL-CONSTRAINTS 테이블 사용해서 조회한다.
select constraint_name, status from ALL_CONSTRAINTS where table_name = 'test';
컬럼에 대한 제약조건 추가/삭제
ALTER TABLE 테이블명 MODIFY 컬럼조건;
desc test01;

ALTER TABLE test01 MODIFY pej varchar(10) not null;

JOIN 의 종류
-JOIN을 통해서 2개 이상의 테이블을 연결할 수 있다.
-JOIN은 기본적으로 기본키나 외부키 값의 연관에 의해 성립되지만,
-논리적인 값들의 연관만으로도 성립할 수 있다.
-JOIN의 조건은 WHERE절에 기술한다.
-JOIN의 방법(종류)는 다음과 같다.
EQUIJOIN(등가조인)
두 개의 테이블 간에 칼럼값들이
정확하게 일치하는 경우에 사용
NON-EQUIJOIN(비등가조인)
두 개의 테이블간에 칼럼값들이
서로 정확하게 일치하지 않는 경우에 사용
OUTER JOIN
두 개의 테이블간에 JOIN을 걸었을 경우
JOIN의 조건을 만족하지 않는 경우에도
그 데이터들을 보고자 하는 경우에 (+)연산자를 사용하는 조인
SELF JOIN
두 개의 테이블들간에 JOIN을 거는 것이 아니라
같은 테이블에 있는 행들을 JOIN하는데 사용
JOIN (실습은 SQL Developer)

테스트할 테이블 구조

tb1 / tb2 테이블

score 테이블
JOIN : 여러 테이블을 조합해서 원하는 데이터 추출
selectp [필드리스트]
from 테이블이름
[join_type] 테이블이름
ON 조건
INNER JOIN : 두 테이블에 같이 존재하는 레코드 연결
INSERT INTO TB1 values('김철수',30);
INSERT INTO TB1 values('이영희',35);
INSERT INTO TB1 values('박영수',40);
INSERT INTO TB1 values('엄근진',45);
INSERT INTO TB2 values('김철수',30);
INSERT INTO TB2 values('김백수',50);
INSERT INTO TB2 values('하희영',55);
- 먼저 조인(JOIN)이란 두 테이블의 결과를 합쳐주는 것을 말한다
위 쿼리문을 보면 TB1(name, age)과 TB2(name, age)를 만들고 값을 넣어줬는데
JOIN을 통해 원하는 조건으로 각 테이블을 합친 결과를 가져올 수 있다는 얘기다
JOIN의 종류는 INNER JOIN, OUTER JOIN이 있는데 예제를 보고 차례대로 알아보자
INNER JOIN(조건과 맞는 것만 가져오는 것!)
SELECT * FROM TB1 A, TB2 B 이후 WHERE 절에서 조건을 만드는데 A.NAME = B.NAME으로 설정하면
TB1 테이블의 NAME과 TB2 테이블의NAME이 같은 행만 가져오게 되는데
TB1과 TB2의 NAME이 동일한 것은 '김철수' 밖에 없으니 김철수만 나오게 된다
쿼리문
select * from tb1 a, tb2 b where a.name = b.name;
select * from tb1 a INNER JOIN tb2 b ON a.name = b.name order by a.name;

OUTER JOIN (기준 테이블 설정 기준테이블의 레코드는 모두 퐇마하고 연관테이블 정보 추가)
쿼리문
-- LEFT OUTER JOIN : 왼쪽 테이블에 값이 있을 시 오른쪽 테이블이 조건에 맞지 않아도 나옴
select * from tb1 a, tb2 b where a.name = b.name(+);
select * from tb1 a left join tb2 b ON a.name = b.name;
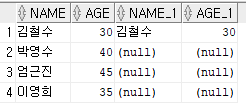
-- RIGHT OUTER JOIN : 오른쪽 테이블에 값이 있을 시 왼쪽 테이블이 조건에 맞지 않아도 나옴
select * from tb1 a, tb2 b where a.name(+) = b.name;

JOIN은 여러 테이블을 조건에 맞춰 가져오는 것이며
INNER JOIN과 (LEFT, RIGHT) OUTER JOIN으로 나눌 수 있는데
INNER JOIN은 조건에 맞는 경우에만 가져오게 되며
(LEFT, RIGHT) OUTER JOIN은 조건에 맞지 않아도
(+)가 붙지 않은 테이블에 값이 있을 경우 값을 가져오게 된다
UNION : 테이블 연결 검색
속성 값을 중복없이 모두 검색
쿼리문
select name, age from tb1 UNION select name, age from tb2;

* 집합연산자
UNION:합집합(중복제외)/ UNION ALL : 합집합(중복포함)
MINUS : 차집합 / INTERSECT:교집합
IN, EXISTS : 중첩 질의.
IN : 다른 테이블에서 어떤 조건으로 검색된 레코드의 정보 추출
-- 점수가 50 초과인 사람의 이름과 나이 검색
select name,age from tb1 where name IN(select name from score where total > 50);
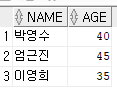

score 테이블을 참조
EXISTS : 존재 여부를 이용한 검색
-- tb1안의 이름에는 있지만 tb2에는 없는 이름 검색
select name from tb1 a where not exists (select name from tb2 b where a.name = b.name);
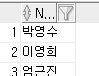
수학 함수
ABS : 절대값
SIN, COS, ... : 삼각함수
CEIL, FLOOR, ROUN : 올림, 내림, 반올림
EXP : 지수
dbms_random.value(0,1) : 0에서 1사이의 난수
문자열 함수
LENGTH : 문자열 길이
LOWER, UPPER : 소문자, 대문자로 변환
LTRIM, RTRIM : 문자열 좌측, 우측 공백 제거
REPLACE : 특정 문자열을 다른 문자열로 바꿈
SUBSTR : 문자열의 특정 부분을 얻음
To_char : 숫자 값을 문자열로 변환
날짜 함수
SYSDATE : 시스템의 날짜와 시각 반환
Extract(YEAR, MONTH, DAY from date) : 날짜에서 년, 월, 일 반환
FOREIGN KEY(외래키)
- 외부키, 외래키, 참조키, 외부 식별자. FK .
- FK가 정의된 테이블을 자식 테이블이라 한다.
- 참조되는 테이블 즉 PK 가 있는 테이블을 부모 테이블이라 한다.
- 부모테이블의 PK 컬럼에 존재하는 데이터만 자식테이블에 입력할 수 있다.
- 부모테이블은 자식의 데이터나 테이블이 삭제된다고 영향을 받지 않는다.
- 참조하는 데이터 컬럼과 데이터 타입이 반드시 일치해야 한다.
- 참조할수 있는 컬럼은 기본키(PK) 이거나 UNIQUE 만 가능하다(보통 PK와 묶임.)
create table score(
name varchar2(20),
total number,
CONSTRAINT fk_code FOREIGN KEY(name) REFERENCES tb1(name) ON DELETE CASCADE
);

CONSTRAINT [제약조건 명] FOREIGN KEY([컬럼명])
REFERENCES [참조할 테이블 이름]([참조할 컬럼])
[ON DELETE CASCADE | ON DELETE SET NULL]
참조할 컬럼과 같은 컬럼이 자식 테이블에 존재해야 한다.
(같은 이름을 쓸필요는없지만 관계를 알아보기 쉽게 같은 컬럼명을 사용.)
그리고 자식테이블에 값을 먼저 넣을수 없다 참조되는 컬럼에 데이터가 있어야 값을 넣을수 있다
ON DELETE CASCADE
- 참조되는 부모 테이블의 행에 대한 DELETE를 허용한다.
즉. 참조되는 부모테이블 값이 삭제되면 연쇄적으로 자식테이블 값 역시 삭제됨.
ON DELETE SET NULL
- 참조되는 부모 테이블의 행에 대한 DELETE를 허용한다.
이건 CASCADE와 다른데 부모테이블의 값이 삭제되면 해당 참조하는 자식테이블의 값들은 NULL값으로 설정됨.
'개발 공부 > SQL, DB' 카테고리의 다른 글
| SQL Developer 사용법과 hr 계정 접속 (0) | 2023.11.23 |
|---|---|
| Oracle SQL로 계정 생성하기(System 아이디 이용) (0) | 2023.11.23 |
| SQL 기본 정리 (0) | 2023.11.23 |
| [Oracle/DBeaver] Java heap space Error, Unhandled event loop exception(Java heap 공간 메모리 늘리기) (0) | 2023.11.22 |
| [MYSQL] No database selected ERROR 해결법 (0) | 2023.11.22 |



